
I noticed an uptick in backlinks to our posts earlier this week and found the site im [dot] news was copying our blog posts word for word and posting them on their site. This is known as scraping content, and while they did include a link at the bottom of the post that said “originally published on Nonprofit Marketing Guide” they are still in violation of copyright as they did not get permission from us nor does it qualify under “Fair Use” laws.
(Please don’t visit the site. It’s all scraped content and you don’t want to give them the ad views. I only included the name here because I thought it would be funny if they scraped this post too.)
Step 1. Contact the Offender
Usually when this happens, I contact the website and they take it down without any reply because they know what they are doing is wrong.
Or sometimes they reply that they thought if they linked back to the original it was fine.
I actually wrote a blog post called Curating Content Versus Stealing It in response to that event if you want to know more about whether you’re quoting content covered under “Fair Use” laws or if you are violating copyright law.
This time though the website has absolutely no contact information at all. No email, no social icons and their name is so generic nothing helpful came up when I did a search.
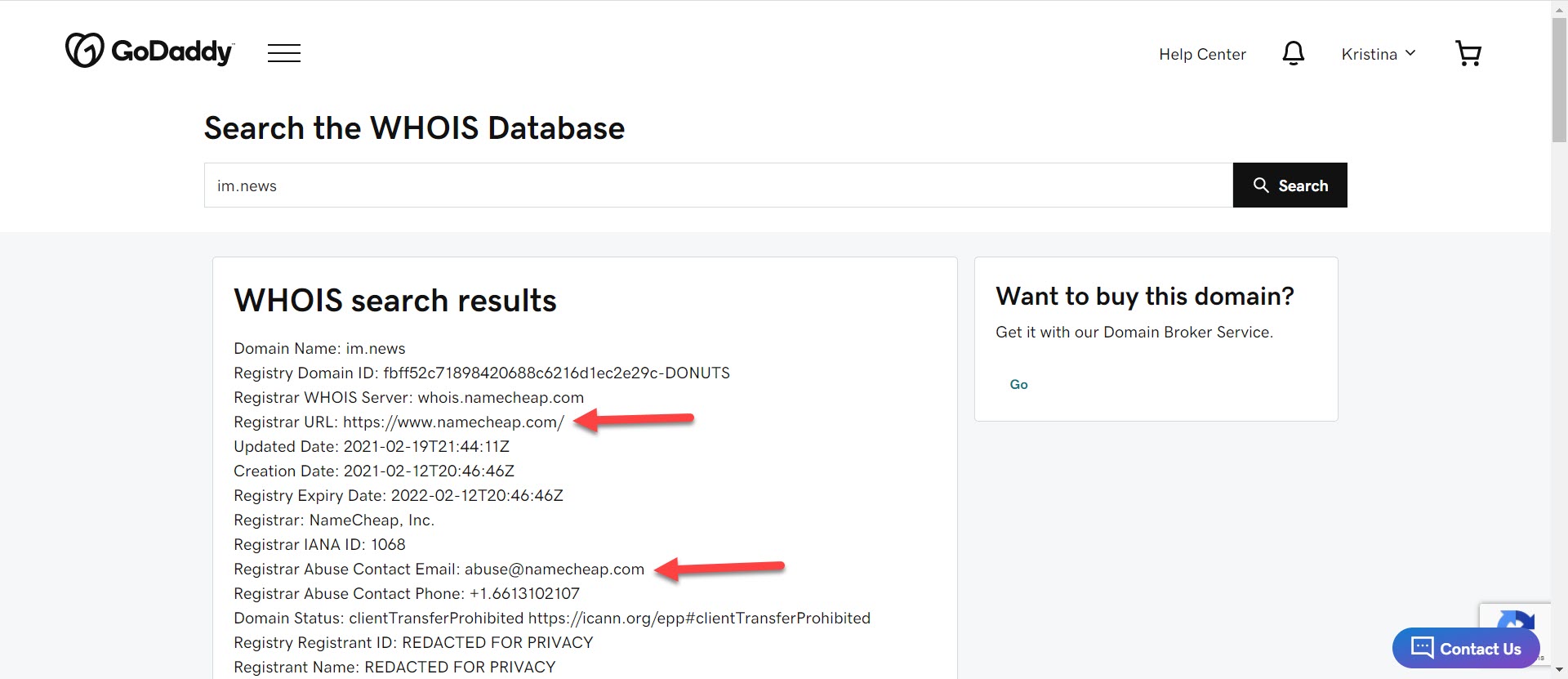
Step 2. Contact the Website Registrar
In cases when you can’t contact the offender or they don’t reply, the next step is take it to the website registrar.
I found this using Godaddy, but you can also go to https://lookup.icann.org/.
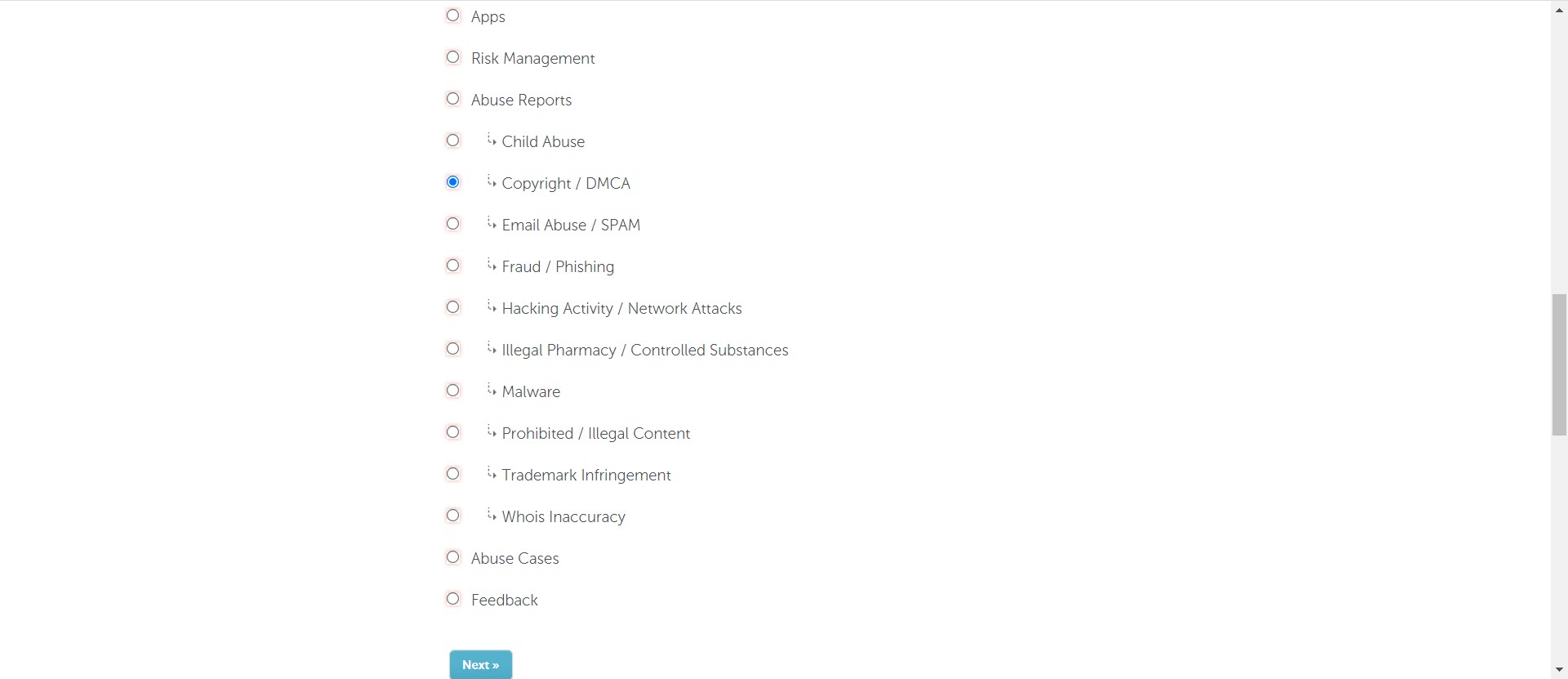
Step 3. File an Abuse Claim (DMCA Takedown)
I used the “Abuse Contact Email” to notify them of the problem. Then after doing a little snooping around their website, I found the specific place to file an official DMCA Takedown request.
Here is what that looked like on their site, but it will vary based on the registrar. I would suggest searching “File DMCA Takedown [Registrar’s Name]” for better results.
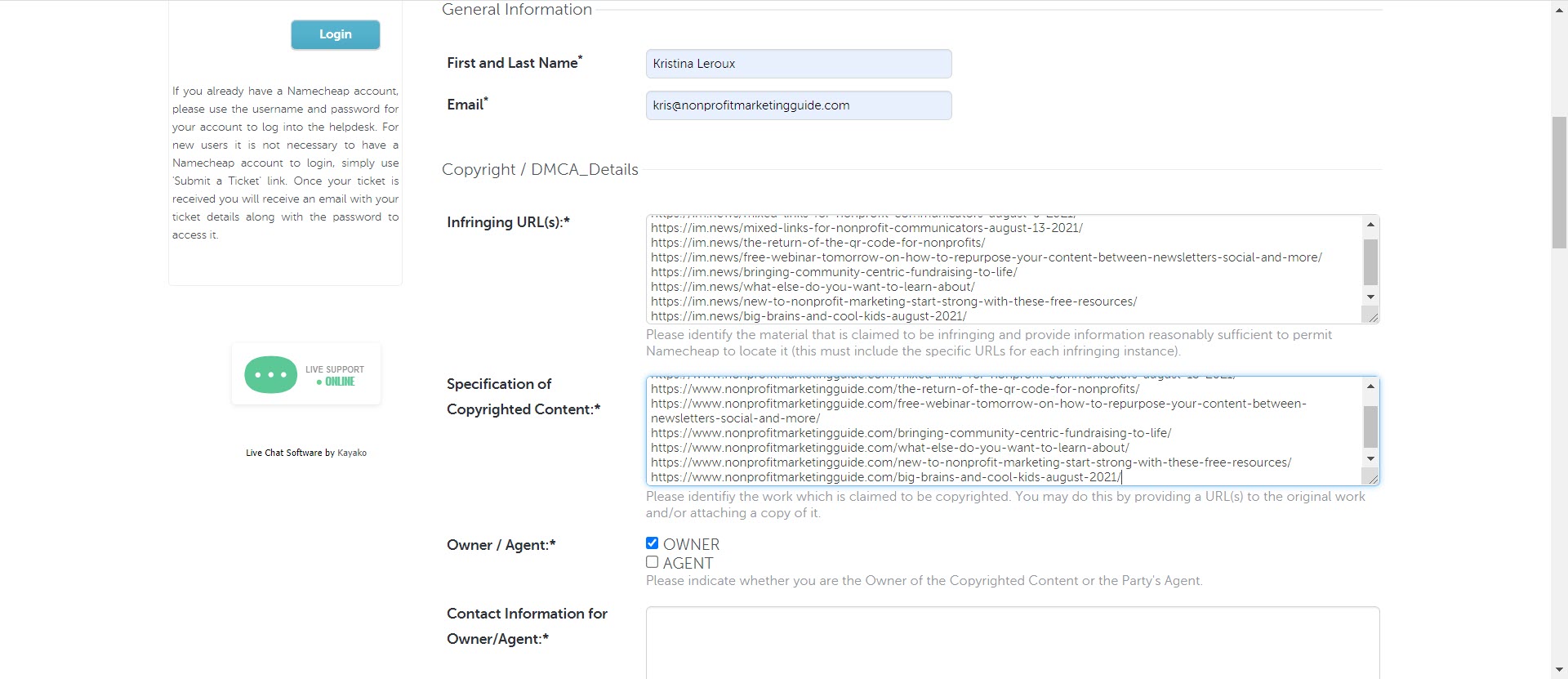
Then I had to fill out the following form that asked for my contact information and every instance of copyright infringement and the link to the original content. That part was pretty tedious since there were so many. (They actually scraped yesterday’s blog post too so I had to email them to add it to the list.)
Here is what the final “ticket” looked like. Again, this will vary based on the registrar. But in all cases you will need to include the links, contact information and agree that you are acting in “good faith” submitting the claim.
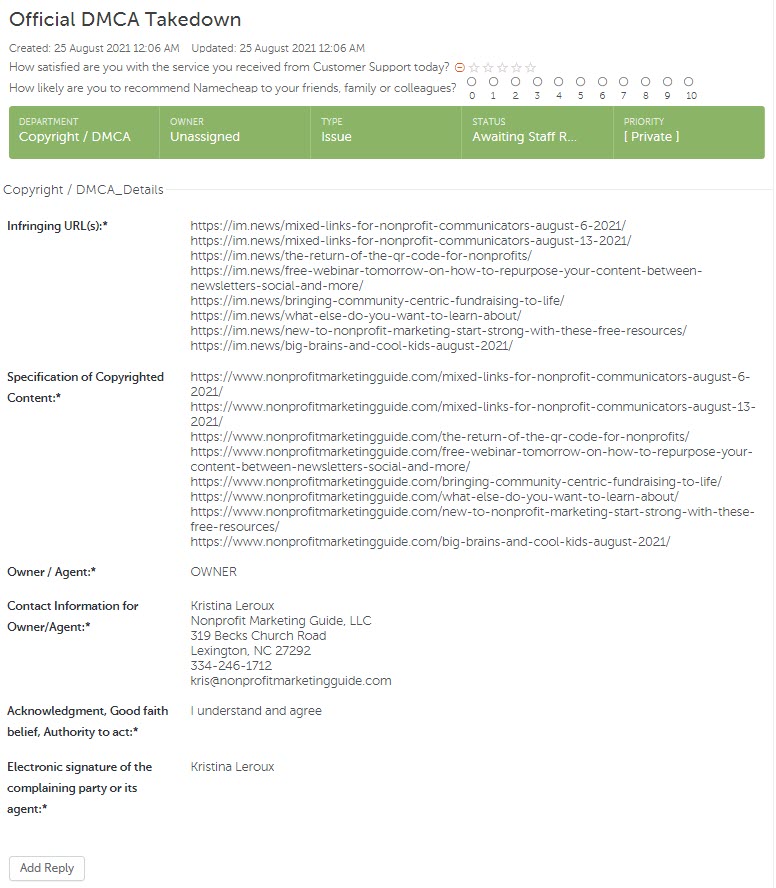
After filing the claim, the registrar set up an account for me so I can monitor the progress.
So now we just wait.
Hopefully they will take everything down, and it won’t be a big deal. But if there is any drama involved, I will update you to let you know next steps.




{kind=link}
{kind=link}
{kind=link}
{kind=link}